-

東京オフィスの移転のお知らせ
平素は格別のご高配を賜り厚く御礼申し上げます。 この度、弊社の東京オフィスは移転することになりましたのでお知らせ申し上げます。 これを機会に、社員一同一層社業に専念いたします。 変わらぬご愛顧のほど、どうぞ宜しくお願い申 […]
-

TC技術検定(テクニカルコミュニケーション技術検定試験)合格への道(3級編)
こんにちは、「トリセツ」担当のマルです。 さて、突然ですが、皆様は「TC検定(テクニカルコミュニケーション技術検定試験)」という資格をご存知でしょうか?メジャーな資格ではないので、聞いたことのない方が大半かと思います。 […]
-

「ウェブサイト」を「ホームページ」と呼ぶことに違和感があった時代
インターネットが普及し始めた1990年頃、コンピュータ上で共有できるシステムとして、「WWW(World Wide Web=ワールド・ワイド・ウェブ)」が一般化して行き、ブラウザというソフトウエアによってホームページが見 […]
-

SEO対策に効果的なtitleタグ(タイトルタグ)の使い方とは?
titleタグ(タイトルタグ)とは、その名のとおりWebページのタイトルを表示するタグです。検索エンジンのクローラーにWebページの内容を簡潔に伝え、GoogleやYahoo!の検索結果に反映させる役割があります。また、 […]
-

InDesignで簡易的な面付をしたPDFの作成方法
こんにちは、「トリセツ」担当のマルです。今回は、InDesignで簡易的な面付けをする方法についてご紹介していきたいと思います。 一般的に「面付け」というと、オフセット印刷のための工程を連想される方も多いかもしれません。 […]
-

グラフィックデザイナーがWebディレクターになるときのスキルアップにはWordPressが必須!?
WordPress(ワードプレス)は、世界で圧倒的なシェアを獲得している無料で使えるオープンソース型のソフトウエアです。CMS「コンテンツ・マネジメント・システム(Contents Management System)」 […]
-

【2023更新】SEOとは?初心者が上位表示するためのSEO対策をわかりやすく解説
SEOとは「Search Engine Optimization 」の略で、日本語で「検索エンジン最適化」を意味します。Googleなどの検索エンジンでキーワードが検索された際に、自サイトを上位に表示させたり、検索流入を […]
-
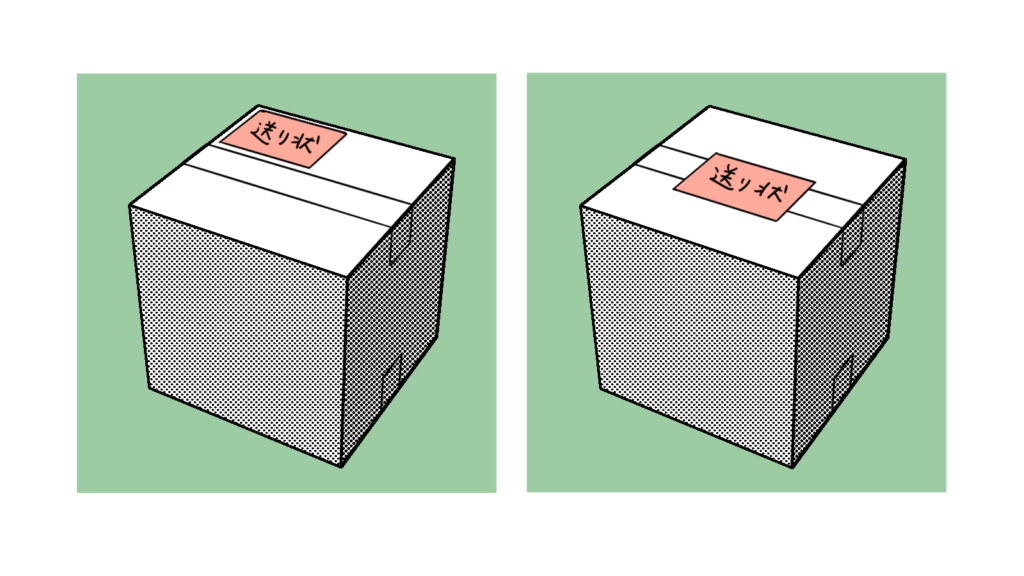
宅配便の送り状どこに貼ってる?
季節は4月、名刺の新規作成だったり会社案内の改訂だったりと新年度を感じる毎日です。出来上がった名刺や冊子を宅配便にて発送することが多い今日この頃、気になることってないでしょうか。「宅配便の送り状って箱のどこに貼るのがいい […]
-

ポストに投函してしまった郵便物を取り戻す方法
みなさん、こういった経験はないでしょうか。郵便物の中身間違いや宛名不良、またはまだ出す予定のなかった郵便物をポストに投函したあとに気づいてしまったという経験。あまり郵便物を出さない、または1回に1通くらいしか出さないとい […]
-

声優さんの収録に立ち合いましたレポ
今回は、アニメーション動画を作るにあたって声優さんに音声を収録して頂いたので、そちらの立ち合いレポをご紹介致します。 ~声優さんを探しに~ 今回声優さんをご紹介頂いたのは 「声のプロダクション 株式会社 キャラ」さま こ […]
BLOG ブログ
